No desenvolvimento de software, muitas vezes nos deparamos com a necessidade de realizar buscas em listas de dados, variando desde pequenos arrays até grandes conjuntos de informações com alto custo computacional. Por vezes, precisamos apenas identificar a existência de um item em um conjunto de dados, o que pode ser computacionalmente custoso. Neste post, irei mostrar duas estruturas de dados que podem solucionar esse problema de forma eficiente.
Introdução
Estruturas de dados probabilísticas são projetadas para fornecer respostas aproximadas às consultas, ou seja, com um grau de incerteza, em vez de retornar uma resposta exata. A vantagem dessas estruturas é que elas oferecem respostas muito mais rápidas e ocupam menos espaço em memória/disco. Essa abordagem implica em uma troca: diminui-se a precisão para ganhar velocidade de resposta e reduzir a utilização de recursos.
Bloom Filter
O Bloom Filter, criado em 1970 por Burton Howard Bloom, é uma estrutura de dados probabilística que responde se um item faz parte de um conjunto de dados com um grau de incerteza, ou se definitivamente o item não faz parte do conjunto. E faz isso de maneira eficiente em relação ao espaço utilizado.
Funcionamento
Um Bloom Filter utiliza um array de bits de tamanho definido e múltiplas funções hash. Cada chave inserida é submetida às N funções hash, e os resultados são utilizados para definir os bits no array de bits. Ao testar uma chave contra o array, caso todos os bits retornem 1, a chave pode fazer parte do conjunto de dados inseridos. Caso algum bit retorne 0, a chave definitivamente não faz parte do conjunto de dados.
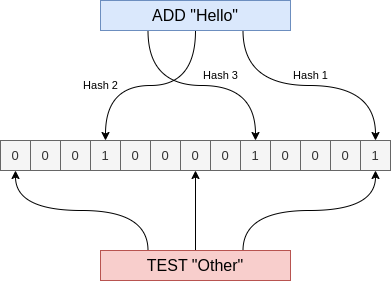
Em alguns casos, pode ocorrer colisão de hash, ou seja, uma string testada retorna todos os bits 1 na consulta, mesmo que não faça parte do conjunto de dados. Em outras palavras, a consulta pode resultar em um falso positivo.
A probabilidade de ocorrer falsos positivos depende do tamanho do array de bits e do número de funções hash. Usar um array de bits maior reduz as chances de colisão, mas ocupa mais espaço. Ter mais funções hash torna o algoritmo mais preciso, mas aumenta o custo computacional para criar e consultar as chaves. É recomendado encontrar um bom equilíbrio nessas configurações.
Implementação em Go
Em Go podemos utilizar o pacote bloom para implementar o Bloom Filter. Irei focar mais em como utilizá-lo pois ele possui alguns métodos interessantes que ajudam a escolher a parâmetrização, e também métodos de estimativa de rate de falso positivo, como mostrarei as seguir que achei muito interessante. Caso queira ver como o algoritmo é feito basta acessar o repositório, o código é relativamente fácil de entender.
Utilização básica
Exemplo de utilização básica semelhante à ilustração acima, utilizando um array de bits de 10 com 3 hash functions.
Estimativa de falsos positivos com base nos parâmetros
Nesse exemplo tem alguns exemplos de estimativas de probabilidade de falso positivo. Perceba como a parâmetrização importa para evitar colisões demais.
Criação com base na quantidade de itens
Outra funcionalidade muito interessante desse pacote é que é possível gerar os parâmetros com base na estimativa de quantidade de itens junto com a quantidade aceitável de falsos positivos.
Cuckoo Filter
O Cuckoo Filter é uma estrutura de dados similar ao Bloom Filter, mas permite além da consulta e adição de chaves, a deleção de chaves do filtro sem a necessidade de ter que gerá-lo novamente. Embora existam algumas implementações alternativas de Bloom Filter que também permitem a deleção, não são tão eficientes quanto o Cuckoo Filter. A complexidade de espaço do Cuckoo Filter é semelhante à do Bloom Filter, tornando-o uma alternativa interessante, especialmente quando a deleção de chaves é necessária.
O Cuckoo filter tem esse nome por ser baseado no cuckoo hashing. Ele utiliza essa estrutura de dados como base e faz algumas adaptações para resolver o problema de set membership.
Seu funcionamento é um pouco mais complicado do que o bloom filter e acaba ficando fora do escopo desse post. Porém, caso haja interesse sugiro a leitura das referências, em especial o artigo original ou então a explicação no site da brilliant, o qual tem uma boa explicação também.
Implementação em Go
Em Go, existe um pacote que implementa o Cuckoo filter utilizando as parametrizações ótimas recomendadas no artigo que deu origem a essa abordagem.
Casos de uso
Existem diversos casos em que podemos resolver problemas utilizando alguma dessas duas estruturas de dados. Alguns lugares em que elas já são aplicadas são os seguintes:
- Senhas muito comuns: consulta se faz parte de um conjunto de senhas mais comuns utilizadas;
- URLs consideradas perigosas: Filtro web;
- Caching: para saber se existe ou não algo em cache;
- Campanhas: para saber se já foi exibida uma propaganda ou não;
- Validação de cupons: para saber se um cupom já foi utilizado ou não.
Um outro caso de uso que não vi em lugar nenhum, porém acredito que em alguns cenários possa ser util se usado em conjunto com filters seria processamento de data streams.
Conclusão
As estruturas de dados probabilísticas representam um conhecimento fundamental para os desenvolvedores. O Bloom Filter e o Cuckoo Filter são exemplos de estruturas que podem resolver problemas complexos que envolvam dados e performance. Vale a pena conhecer essas ferramentas e explorar suas aplicações em projetos de software.
Referências
- Livro: Database Internals (Alex Petrov) - Página 147;
- https://www.geeksforgeeks.org/introduction-to-the-probabilistic-data-structure/
- https://eximia.co/como-bloom-filter-pode-ser-utilizada-para-melhorar-a-performance/
- https://redis.io/docs/data-types/probabilistic/bloom-filter/
- https://redis.io/docs/data-types/probabilistic/cuckoo-filter/
- https://www.cs.cmu.edu/~dga/papers/cuckoo-conext2014.pdf
- https://brilliant.org/wiki/cuckoo-filter/
- https://github.com/bits-and-blooms/bloom