
Recentemente precisei implementar uma funcionalidade onde uma lambda consumia as mensagens de uma fila SQS, transformava os dados e fazia uma requisição para o endpoint correto com base na mensagem recebida e suas configurações.
O cenário base era algo semelhante ao da imagem a seguir:
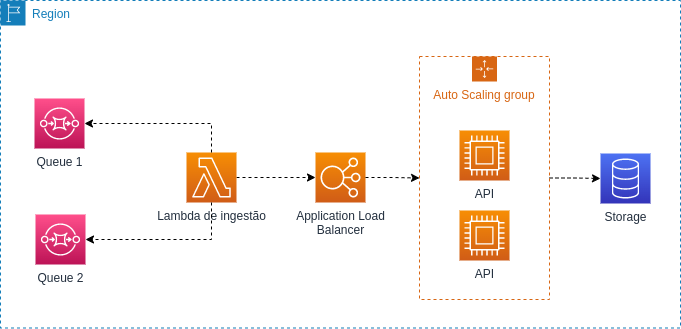
É a partir desse cenário que vou mostrar o problema poison pill e como resolvê-lo.
Problema (Poison Pill)
O processamento das mensagens pela lambda é feito através de polling. Ou seja, a lambda faz uma requisição para receber as mensagens da fila. É comum receber as mensagens da fila em lotes, para que sejam necessárias fazer menos invocações da lambda e também que gaste menos com requisições feitas para o SQS.
O problema nesse caso acontece caso haja uma falha no meio desse lote de mensagens. Caso ocorra erro em 1 única mensagem, o lote inteiro pode ser invalidado e terá que ser reprocessado. Essa mensagem chamamos de poison pill.
Solução
Para solucionar esse tipo de problema nessa integração lambda+sqs, a AWS implementou uma maneira de indicar quais mensagens tiveram sucesso e quais tiveram falhas no meio do lote das mensagens. Isso é feito retornando o um objeto com o campo BatchItemFailures, junto com as mensagens que deram problema.
Um exemplo de implementação em Go segue uma estrutura semelhante a essa:
| |
Nesse exemplo, tem adicionei a simulação de um erro com 20% de chance
de ocorrer no processamento com rand.Intn(10) < 2. Nesse caso, eventualmente
ocorreria um erro na lambda e apenas as mensagens que deram erro voltam para a fila.
As outras mensagens são deletadas e são consideradas sucesso.
Reparem que o ID da mensagem é retornado dentro do item do batchItemFailure
e é através dele que sabe-se que uma mensagem foi processada com sucesso ou não.
Um ponto bastante importante dessa configuração é que deve ser configurado o parâmetro
function-response-types para “ReportBatchItemFailures”. Essa configuração, até o momento do post
não é possível fazer pelo console da AWS. Somente pela CLI, e o comando é o seguinte:
| |
Nos exemplos de código,
Exemplo de implementação completo
Implementei um terraform para subir uma estrutura como essa descrita no post com esse mesmo código da lambda. Caso tenha curiosidade e queira rodar, ele está localizado no link https://github.com/leometzger/leometzger.github.io-code-examples/tree/main/lambda-sqs-partial-return.
Como rodar o template do terraform não é o objetivo desse post. Como rodar o exemplo está descrito no código do repositório. Caso queira reproduzir o mesmo exemplo, sintam-se a vontade.
Conclusão
A utilização do batchItemFailures é bastante útil e pode gerar uma boa redução de custo no cenário onde a lambda é invocada muitas vezes e ocorra algumas falhas eventuais. Além disso, permite que você evite de gastar com processamento e reenvio dos dados caso não seja necessário. Também habilita a possibilidade de usar sempre o processamento em lotes na lambda, podendo melhorar o desempenho do sistema como um todo.